결론
supabase 기준, Sqlalchemy의 비동기 엔진에서 Postgresql pooler (supavisor)에 오류 없이 연결하기 위해서는 create_async_engine 을 다음과 같이 구성해주면 된다.
from uuid import uuid4
from asyncpg import Connection
...(생략)...
class CConnection(Connection):
def _get_unique_id(self, prefix: str) -> str:
"""
캐싱을 만들 시에 캐싱 아이디가 중복으로 생성되어서 오류가 발생하는 경우가 있다.
statement_cache_size를 0으로 해도 일단 캐싱을 만들고 오류를 낸다.
따라서 캐싱을 사용하지 않을 것이므로, 아예 중복되지 않게 UUID로 생성해버린다.
"""
return f'__asyncpg_{prefix}_{uuid4()}__'
...(생략)...
DATABASE_URL = f"postgresql+asyncpg://postgres.[Project ID]:[Password]@aws-0-[Region].pooler.supabase.com:6543/postgres?prepared_statement_cache_size=0"
_db_connection = create_async_engine(
DATABASE_URL,
connect_args={
"statement_cache_size": 0,
'connection_class': CConnection,
},
)statementcachesize, preparedstatementcache_size를 둘 다 모두 0으로 줘야 한다.
그리고 왜 발생하는지 모르겠는 간헐적인 오류(캐싱 ID를 중복되게 생성하려고 시도함)를 해결하기 위해 Connection 클래스를 상속받아 getuniqueid 메소드를 오버라이딩 해주고, 해당 클래스를 connectionclass로 사용하도록 했다. 이렇게 하면 id 중복 생성 오류를 방지할 수 있다.
일반적인 글이라면 결론이 서두에 나온다면 너무나 시시하겠지만 기술 블로그이니 괜찮다.
문제 해결에 관한 글
발단
supabase에서 메일이 왔다.
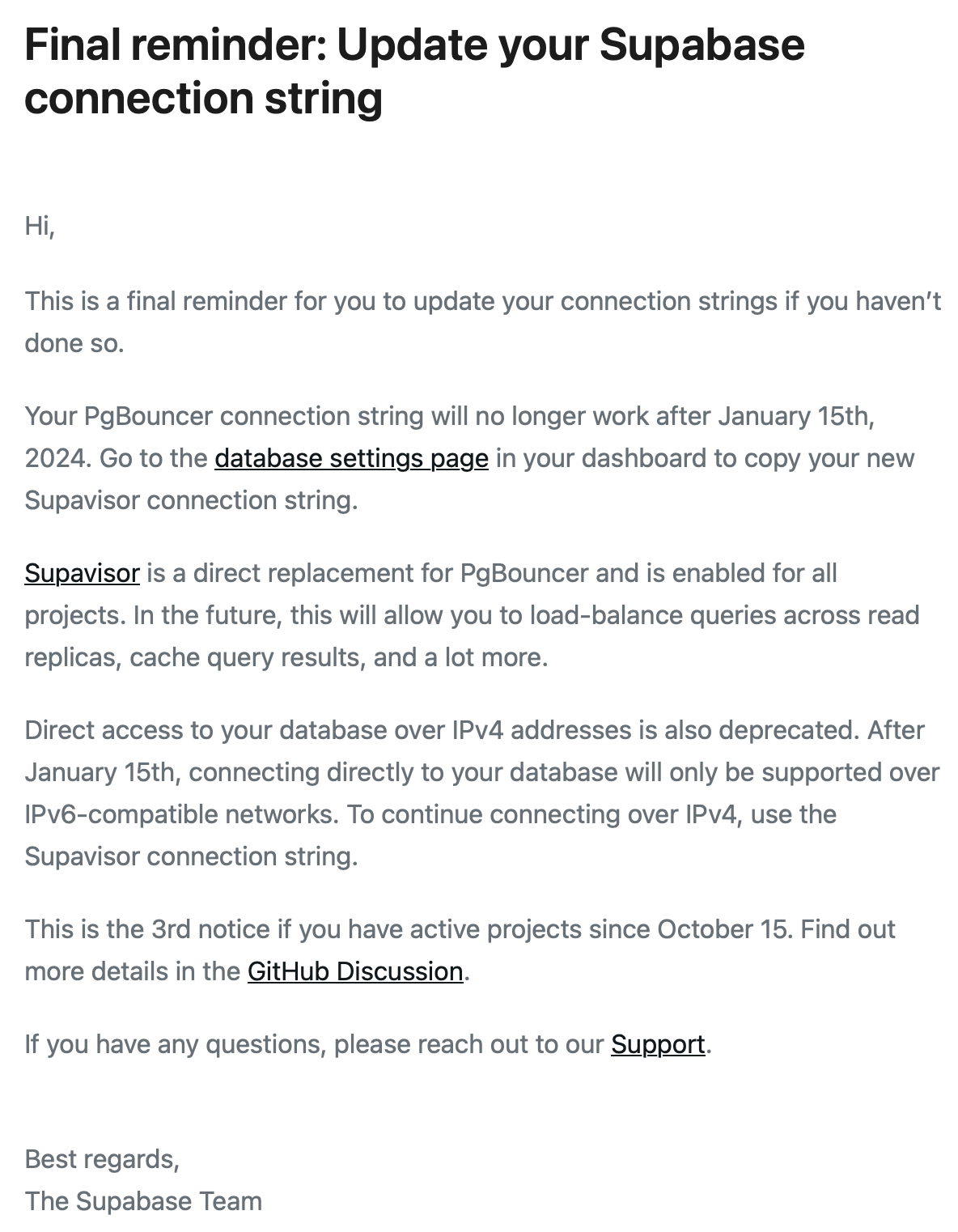 여태 본 기억이 없었는데, Final reminder라도 되어있는걸 보니 이미 여러번 고지했던 모양이다.
여태 본 기억이 없었는데, Final reminder라도 되어있는걸 보니 이미 여러번 고지했던 모양이다.
읽어보니 Pgbouncer 지원이 종료된다는 내용이다. 지원이 종료되는건 알고 있었는데, 아예 Connection string을 죽여버리는 모양이다. 잔인하다는 생각이 들었지만 어차피 우리는 Pooler는 진작에 포기했으므로 상관이 없었다.
문제는 다음이었는데, DB Direct access에 대한 IPv4 주소 지원도 끝난다니 이건 좀 문제의 소지가 있었다.
마침 어제 지난번 DB 세팅에 대한 회고를 끝내서 다행이었다.
전개
선택지는 두가지이다. Supavisor 도입, 네트워크가 IPv6를 지원하도록 설정하고 Direct 연결 방법을 계속해서 사용.
개인적으로
- 네트워크 설정에 상대적으로 약함
- WebRTC를 하던 때의 기억 때문에 IPv6에 안좋은 감정이 있음
- 현재 백엔드의 네트워크 설정을 직접 진행하지 않았었음
- 혼자 출근한 백엔드는 나 혼자임
- Pooler와 씨름을 한 기억이 최근이고, 회고는 더더욱 최근임
의 이유로 Supavisor 도입에 대해 다른 백엔드가 출근하기 전 잠깐 살펴보기로 했다.
그런데 왠걸? 직접 설치부터 해야 하나라고 막연히 생각을 했었는데(supabase의 공식 문서에는 아직 supavisor에 대한 내용이 적어도 찾기 쉬운 곳에 있지는 않다. ) 그렇지 않았다.
https://github.com/orgs/supabase/discussions/17817
해당 링크를 보아하니 이미 꽤 지원이 진행된 상태였는지, connection string만 바꾸면 간단하게 Pgbouncer가 아니라 Supavisor를 사용하여 연결할 수 있다고 적혀 있었다.
그래서 해당 링크를 참조해 Connection string은 약간 수정을 해야 했지만, 어쨌든 Supavisor 연결에 간단하게 성공해버렸다.
위기
곧장 과거 겪었던 것과 같은 문제가 발생했다. Sqlalchemy 입장에서는 Pgbouncer와 Supavisor를 따로 구분하지 못하는지 Transaction 또는 Session 풀 모드에서는 캐싱이 지원되지 않는다는 에러 문구가 발생했다.
여기서 잠깐, 포기하고 얌전히 IPv6 설정을 보러 갈까 했는데, 아직 다른 백엔드가 아무도 출근하지 않았다.
일단 Pool mode를 바꿔야 다음 단계의 설정을 진행할 수 있었는데, Pgbouncer의 Pool mode는 supabase 콘솔에서 세팅을 지원하지만 supavisor는 어떻게 바꿔야 할지 의문이었다.
해당 의문은 말도 못하게 간단하게 풀렸다. 콘솔에 들어가보니 어느새 쥐도 새도 모르게 Pgbouncer 관련 섹션이 supavisor 관련 섹션으로 바뀌어있었다.
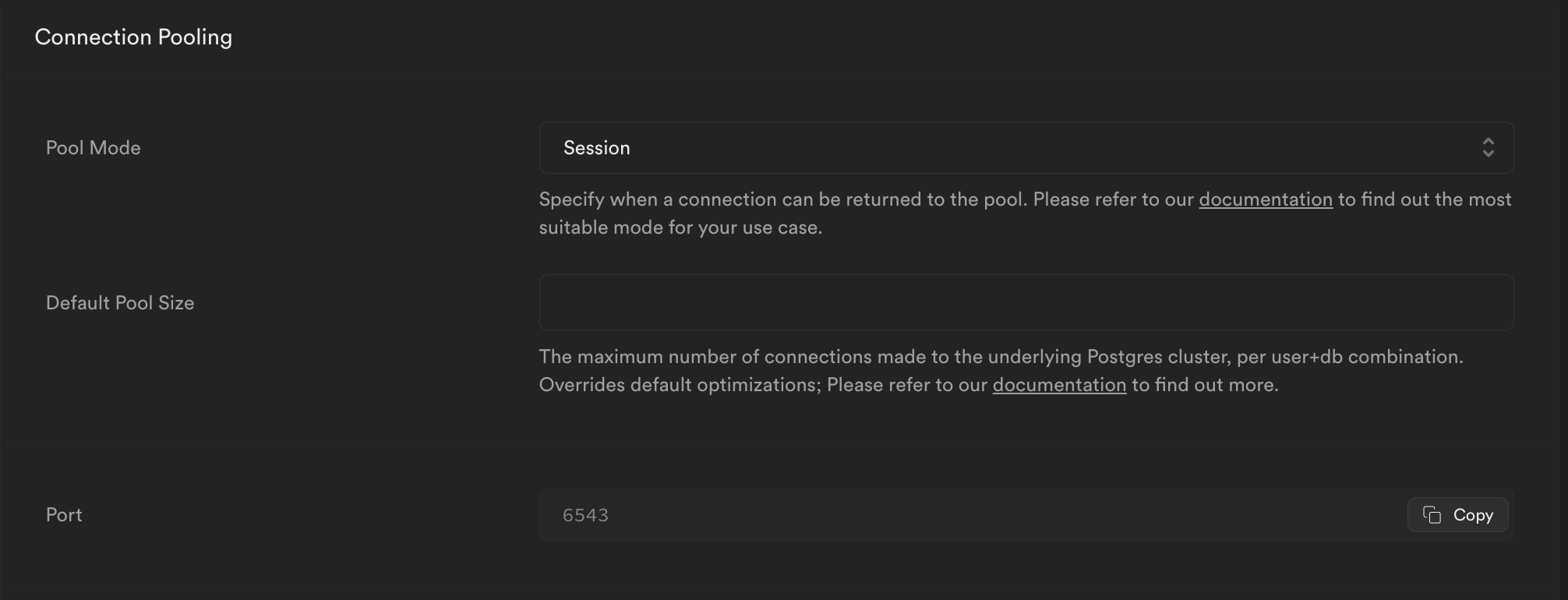 위 이슈에서 설명된 supavisor 관련 connection string은
위 이슈에서 설명된 supavisor 관련 connection string은 user 로 시작하는 부분이 옳지 않아서 수정이 필요했는데, 콘솔의 pgbouncer 관련 연결 connection string 에는 제대로 적혀있었다. 아무래도 메일에 적어보낸 이슈이지만 따로 수정을 하지는 않은 모양이다..
아무튼간 pool mode를 변경 후 테스트를 할 수 있었다.
절정1
Pool mode를 바꿨다고 해서 바로 연결이 가능하지는 않다. 서버 인스턴스를 실행하면 짜잔! 성공적인 DB 연결 대신 다음과 같은 문구를 볼 수 있다.
sqlalchemy.exc.DBAPIError: (sqlalchemy.dialects.postgresql.asyncpg.Error) <class 'asyncpg.exceptions.InvalidSQLStatementNameError'>: prepared statement "__asyncpg_stmt_b__" does not exist
HINT:
NOTE: pgbouncer with pool_mode set to "transaction" or
"statement" does not support prepared statements properly.
You have two options:
* if you are using pgbouncer for connection pooling to a
single server, switch to the connection pool functionality
provided by asyncpg, it is a much better option for this
purpose;
* if you have no option of avoiding the use of pgbouncer,
then you can set statement_cache_size to 0 when creating
the asyncpg connection object.Sqlalchemy를 사용중이기 때문에 첫번째 방법은 자연스럽게 더 고려할것도 없이 기각이며, statementcachesize를 0으로 수정하는 것이 현재 내 인프라에서 선택할 수 있는 방법이었다.
https://docs.sqlalchemy.org/en/20/dialects/postgresql.html
지난번 기나긴 고생 이후 공식 문서를 항상 참조하는 습관을 들이게 됐다. 아주 긍정적인 방향이라고 생각한다.
공식 문서를 참조하면,
engine = create_async_engine("postgresql+asyncpg://user:pass@hostname/dbname?prepared_statement_cache_size=0")의 방식으로 statementcachesize를 0으로 설정할 수 있는 것을 알 수 있다.
이 설정을 해준 후, 다시 서버 인스턴스를 실행하면 짜잔! DB 연결이 아주 잘 된다. 쿼리도 잘 날리고, 결과도 잘 받아온다.
이 와중에 Cache 생성 시에 같은 인덱스로 중복 생성되어서 오류가 발생하기도 했다. 그래서 SqlAlchemy의 Connection 클래스를 상속받아 캐시의 아이디를 생성하는 메소드를 수정해주었다.
from asyncpg import Connection
from uuid import uuid4
class CConnection(Connection):
def _get_unique_id(self, prefix: str) -> str:
"""
캐싱을 만들 시에 캐싱 아이디가 중복으로 생성되어서 오류가 발생하는 경우가 있다.
statement_cache_size를 0으로 해도 일단 캐싱을 만들고 오류를 낸다.
따라서 캐싱을 사용하지 않을 것이므로, 아예 중복되지 않게 UUID로 생성해버린다.
"""
return f'__asyncpg_{prefix}_{uuid4()}__'이후 DB 커넥션을 만들 때에 해당 클래스를 기본 Connection 클래스 대신 사용하도록 설정해주면 된다.
DATABASE_URL = f"postgresql+asyncpg://postgres.[Project ID]:[Password]@aws-0-[Region].pooler.supabase.com:6543/postgres?prepared_statement_cache_size=0"
_db_connection = create_async_engine(
DATABASE_URL,
connect_args={
'connection_class': CConnection,
},
)여기까지 작업을 해줘서 오류를 해결하고 같은 쿼리를 연속으로 날리면?
짜잔! 다음과 같은 오류를 볼 수 있다.
sqlalchemy.exc.DBAPIError: (sqlalchemy.dialects.postgresql.asyncpg.Error) <class 'asyncpg.exceptions.InvalidSQLStatementNameError'>: prepared statement "__asyncpg_stmt_9462b5fe-88dc-46f5-98fb-57981ea56de0__" does not exist
HINT:
NOTE: pgbouncer with pool_mode set to "transaction" or
"statement" does not support prepared statements properly.
You have two options:
* if you are using pgbouncer for connection pooling to a
single server, switch to the connection pool functionality
provided by asyncpg, it is a much better option for this
purpose;
* if you have no option of avoiding the use of pgbouncer,
then you can set statement_cache_size to 0 when creating
the asyncpg connection object.그렇다, 오류는 반복된다.
절정2
이미 여기까지 시간을 꽤 쓴 상태였기 때문에 조금만 더 무언가를 해보기로 했다.
캐시 사용을 아무리 꺼도, 도대체가 캐시를 계속 만들고 거기서 오류를 내는 이 상황.
다행히 비슷한 오류를 겪는 사람들을 깃허브 이슈에서 찾을 수 있었다.
이미 나의 신뢰를 많이 잃어버린 챗지피티에게 이 문제를 상담하면 statement_cache_size 옵션을 0으로 설정해서 connect_args에 넣으라고 한다. PgBouncer로 붙이려고 애써봤었을 때에 해당 옵션을 넣어도 아무런 변화가 없이 그대로 오류가 발생했었고, 공식문서에는 존재하지 않는 옵션이어서 이번에는 무시하고 넘어갔었다.
근데 충격적이게도 한가지 옵션을 썼을 땐 되지 않고 두 옵션을 동시에 사용하면 된다고 한다.. 이게 무슨 일일까? 나는 왜 두 옵션을 동시에 쓸 생각을 못했을까?(이 생각을 어떻게 하나요?)
최종적으로 DB Connection String을 다음과 같이 설정해주었다.
from uuid import uuid4
from asyncpg import Connection
...(생략)...
class CConnection(Connection):
def _get_unique_id(self, prefix: str) -> str:
"""
캐싱을 만들 시에 캐싱 아이디가 중복으로 생성되어서 오류가 발생하는 경우가 있다.
statement_cache_size를 0으로 해도 일단 캐싱을 만들고 오류를 낸다.
따라서 캐싱을 사용하지 않을 것이므로, 아예 중복되지 않게 UUID로 생성해버린다.
"""
return f'__asyncpg_{prefix}_{uuid4()}__'
...(생략)...
DATABASE_URL = f"postgresql+asyncpg://postgres.[Project ID]:[Password]@aws-0-[Region].pooler.supabase.com:6543/postgres?prepared_statement_cache_size=0"
_db_connection = create_async_engine(
DATABASE_URL,
connect_args={
"statement_cache_size": 0,
'connection_class': CConnection,
},
)결말 & 에필로그
지난번 기나긴 고생과 삽질을 통해서 챗지피티에 대한 신뢰를 덜고 공식문서를 신뢰해야 한다는 사실을 깨달았다.
그리고 이번 짧은(반나절 정도) 삽질을 통해서 공식문서도 100% 정답은 아니라는 사실을 깨달았다. (나는 무엇을 믿어야 할까?)
생각해보면, Database url 에다가 옵션을 넣는다고 해서 내부적으로 뭔가 변경되는 것일리가 없다. 결국 엔진을 만들 때에 옵션값을 넣어줘야 내부적으로 뭔가 알고 다른 작동을 하지 않을까? 이 생각을 막바지에 와서 떠올렸다.
항상 시야를 넓게 하고, 의심하면서 만들어야 한다는 것을 다시 한 번 깨달았다. 남들이 시키는대로 해서는 되는것이 없는 것이다.
별개로, 내가 잘못을 한 것인지 뭔지 Sqlalchemy도 FastAPI도 Postgresql도 모두 유명한 것들인데 어째서 이렇게까지 불완전하게 작동하는지 의문이 든다. 역사가 길진 않지만 그래도 수년의 시간은 지난 것들인데, 가장 기본적인 부분이 이렇게 불안정할지는 예상을 못했다. FastAPI의 메모리 누수 문제도 뒤늦게 알게 되었는데, 메모리 누수 문제에 이어서 비동기 엔진에서의 DB Pooler 연결에 이렇게 문제가 있을 줄 알았다면 FastAPI와 SqlAlchemy를 절대 선택하지 않았을 것 같다.
고찰, 의심, 경험.. 등등이 중요하다고 다시 한 번 느꼈다.